J2EE/EJB, Jáva az alkalmazásszerverekben
Paller Gábor1. Három- és többrétegű szerver alkalmazásmodellek
A klasszikus elosztott
alkalmazásmodel a kliens-szerver modell. Ebben a modellben egy
számítógép mindig tisztán a kliens
vagy a szerver szerepét játsza. A szervereket bizonyos
konkrét részfeladatok elvégzésére
specializálják, pl. fájlok
tárolására, nyomtatásra,
adatbázisműveletekre, stb. A klienseken futó
alkalmazások tartalmazzák magát az
alkalmazáslogikát, ez az alkalmazáslogika
valósítja meg magát a felhasználói
funkcionalitást, eközben szervereken tárolt
erőforrásokat használ fel. Tipikus kliens-szerver modell
a tradicionális adatbáziskliens-adatbázisszerver
felállás, ahol a kliens SQL mondatokat küld a
szervernek és az eredményeket pedig felhasználja a
felhasználóval való kommunikációban.
A webes és mobil alkalmazástechnológiák elterjedése miatt fontosak lettek az u.n. vékony kliensek. Vékony kliens lehet egy böngésző vagy egy MIDletet futtató mobiltelefon. Közös jellemzőjük, hogy a kliens nem képes a teljes alkalmazáslogikát megvalósítani, mert a kliensplatform túl korlátozott. A szerepek és szereplők a következőképpen alakulnak.
2. A J2EE és architektúrája
A J2EE (Java 2 Enterprise Edition) egy szabványsorozat. A J2EE
célja, hogy egy gazdag szerveroldali API-készletet
nyújtson a fejlesztőknek. A szabványsorozat legfontosabb
elemei a következők:
A J2EE architektúra az előző fejezetben említett négyrétegű modellre alapul. A J2EE-ben a rétegek a következőképpen néznek ki.
Az EJB alkalmazásmodellnek azon ígérete, hogy alkalmazásaink extrém skálázhatósági követelményeknek is eleget tudnak majd tenni (megfelelő számítógéprendszeren és alkalmazásszerverrel) komoly megkötésekkel jár. Ehhez az kell, hogy az alkalmazás ne tartalmazzon semmit, ami egy bizonyos számítógéphez köti és az alkalmazásszerver nem tud róla. Példák a megkötésekre:
A konténer szolgáltatásai közül az EJB katalógussal kezdeném, mert arra sok minden épül. Minden EJB konténernek része egy JNDI katalógus (Java Naming and Directory Interface, javax.naming csomag) . A JNDI egy interfész csupán, a mögötte levő katalógustechnológia tetszőleges lehet (pl. LDAP). A JNDI egy hierarchikus adatstruktúrára épül, amely sokban hasonlít a szokásos fájlrendszerek könyvtárszerkezetére. Egy katalóguselem eléréséhez három dolgot kell tudnunk: a sémát, ami alatt a katalógus tárolja, az őt befoglaló kontextusok listáját, végül a nevet, ami alatt a katalógusban tároljuk. A kontextus teljesen analóg a könyvtárnévvel, míg a név a fájlnévvel. Egy JNDI név például így nézhet ki: java:comp/env/MyBean. Ezt a katalóguselemet így érhetjük el:
javax.naming.Context initial = new javax.naming.InitialContext();
Object objref = initial.lookup("java:comp/env/MyBean");
A webes és mobil alkalmazástechnológiák elterjedése miatt fontosak lettek az u.n. vékony kliensek. Vékony kliens lehet egy böngésző vagy egy MIDletet futtató mobiltelefon. Közös jellemzőjük, hogy a kliens nem képes a teljes alkalmazáslogikát megvalósítani, mert a kliensplatform túl korlátozott. A szerepek és szereplők a következőképpen alakulnak.
- Kliens: felelős a felhasználói felületért és a felhasználóval való kapcsolattartásért
- Alkalmazásszerver: itt van az alkalmazáslogika és ez felelős a szervererőforrások eléréséért
- Erőforrásszerver: ez a hagyományos szerver (pl. fájlszerver vagy SQL szerver)
- Kliens
- Kliens-szerver protokolkezelő (pl. HTTP), felhasználói felülettel kapcsolatos programrészek
- Tiszta alkalmazáslogika ("business logic")
- Erőforrásszerver
2. A J2EE és architektúrája
A J2EE (Java 2 Enterprise Edition) egy szabványsorozat. A J2EE
célja, hogy egy gazdag szerveroldali API-készletet
nyújtson a fejlesztőknek. A szabványsorozat legfontosabb
elemei a következők:- Jáva szervlet/JSP
- Enterprise JavaBeans (EJB)
- Java Message Service (JMS)
- Java Database Connectivity (JDBC)
A J2EE architektúra az előző fejezetben említett négyrétegű modellre alapul. A J2EE-ben a rétegek a következőképpen néznek ki.
- Kliens. Ha a kliens webes, vagy HTTP alapú, akkor a webszerver réteghez kapcsolódik ("vékony kliens"). Másik lehetőség, hogy saját felhasználói felülettel rendelkezik és HTTP-t nem akar használni, ekkor csatlakozhat közvetlenül az alkalmazásszerverhez is.
- Web-réteg. Ez webszervert és a benne futó alkalmazáslogika-részt, tipikusan felhasználói felülettel kapcsolatos vagy HTTP forgalom kezelésével kapcsolatos részt jelent. Ennek a rétegnek az alkalmazásmodellje a szervlet/JSP.
- Alkalmazásszerver réteg. Itt az alkalmazáslogika felhasználói felülettől független részei vannak. Ennek a rétegnek az alkalmazásmodellje az Enterprise JavaBeans (EJB).
- Erőforrásszerver. Habár a J2EE tetszőleges erőforrásszervert tud használni, igazából SQL adatbázisszerverekre van kihegyezve.
3. EJB-k és EJB konténer
A mi tárgyunk alkalmazásmodellekkel foglalkozik, tehát a J2EE alkalmazásmodelljei iránt érdeklődünk. A szervlet/JSP már ismert, így itt az EJB-re koncentrálunk. Hasonlóan a szervletekhez, az EJB is a konténer patternre épül. A konténer pattern azt jelenti, hogy az alkalmazási területen a lefedni kívánt alkalmazásokból "kivonjuk" a közös funkciókat és a konténerben koncentráljuk. Ezek után a konténer és az alkalmazás szigorúan alkalmazásspecifikus darabjai (az alkalmazáslogika) között interfészt definiálunk. Ezt tettük a webalkalmazásoknál, amikor a szervlet és szervletkonténer közötti interfészt definiáltuk. Akkor a HTTP-kezelés és a célcímnek megfelelő erőforrás elérése volt a konténer dolga. Most az alkalmazáslogika elemeit kötött interfésszel rendelkező Jáva osztályokban, Enterprise JavaBeans komponensekben implementáljuk és az EJB-ket regisztráljuk az EJB konténernél. Az EJB konténernél a konténer funkciói a következők:- Az EJB-k életciklusának vezérlése, az EJB-k létrehozása és elpusztítása
- Az EJB-k egymással való kommunikációjának lehetővé tétele, egyik EJB hívása a másikból
- Az EJB-k elérhetőségének biztosítása a kliensek felől
- Az EJB-k hozzáférésésének ellenőrzése, autentikációs és autorizációs szabályok betartatása
- Az EJB-k katalógusának
nyilvántartása, hogy a kliensek és más
EJB-k név szerint hivatkozhassanak az EJB-re
- Az adatbázishoz való hozzáférés ellenőrzése, kényelmesebb adatbáziselérés biztosítása
Az EJB alkalmazásmodellnek azon ígérete, hogy alkalmazásaink extrém skálázhatósági követelményeknek is eleget tudnak majd tenni (megfelelő számítógéprendszeren és alkalmazásszerverrel) komoly megkötésekkel jár. Ehhez az kell, hogy az alkalmazás ne tartalmazzon semmit, ami egy bizonyos számítógéphez köti és az alkalmazásszerver nem tud róla. Példák a megkötésekre:
- Az EJB nem hozhat létre végrehajtási szálakat, hiszen egy végrehajtási szálat nem lehet áttenni egy másik számítógépre.
- Az EJB nem használhat fájlokat a helyi fájlrendszeren, hiszen ha a bean következő hívásakor egy másik számítógépen fut le, a fájl nem lesz elérhető. Fájlszerver is óvatossággal használandó, két EJB hívás között a fájl nem hagyható nyitva, mert a helyi erőforrás (fájldeszkriptor) állapotáról a szervercsoport másik tagja nem tud, márpedig túlterhelés vagy hiba esetén a bean egy másik gépre kerülhet.
- Az EJB nem kezelhet hálózatot se, hiszen pl. egy socket olyan erőforrás, amit nem lehet más gépre mozgatni.
A konténer szolgáltatásai közül az EJB katalógussal kezdeném, mert arra sok minden épül. Minden EJB konténernek része egy JNDI katalógus (Java Naming and Directory Interface, javax.naming csomag) . A JNDI egy interfész csupán, a mögötte levő katalógustechnológia tetszőleges lehet (pl. LDAP). A JNDI egy hierarchikus adatstruktúrára épül, amely sokban hasonlít a szokásos fájlrendszerek könyvtárszerkezetére. Egy katalóguselem eléréséhez három dolgot kell tudnunk: a sémát, ami alatt a katalógus tárolja, az őt befoglaló kontextusok listáját, végül a nevet, ami alatt a katalógusban tároljuk. A kontextus teljesen analóg a könyvtárnévvel, míg a név a fájlnévvel. Egy JNDI név például így nézhet ki: java:comp/env/MyBean. Ezt a katalóguselemet így érhetjük el:
javax.naming.Context initial = new javax.naming.InitialContext();
Object objref = initial.lookup("java:comp/env/MyBean");
A JNDI katalóguselemeknek
típusa is van. A lookup metódus Object referenciát
ad vissza, amit át lehet alakítani a megfelelő
típusra. A JNDI tetszőleges objektumok egyedeit it tudja
tárolni, ezt az EJB ki is használja.
Az EJB-knek négy alaptípusa van:
3.1. Állapot nélküli kapcsolat bean (stateless
session bean)
Lássuk a legegyszerűbbet, az állapot nélküli
kapcsolat bean-t. Ez a bean lehetővé teszi metódusok
kontextus nélküli hívását,
tehát a metódushívások között a
konténer nem őriz állapotot, a kontextus csupán a
hívás során létezik. A kliensprogram a
bean-t a create() metódus meghívásával
létrehozza, majd az így kapott bean egyeden meghív
egy bean által implementált metódust. A
hívás során a bean egyedváltozói
megőrződnek, de egyáltalán nem garantált, hogy a
következő hívásnál ugyanazon a bean egyeden
hajtódik végre a hívás vagy hogy
közben a konténer nem adta-e oda a bean egyedet egy
másik kliensnek egy másik hívásra. A bean
egyedváltozói tehát nem használhatók
hívások közötti állapot
tárolására. A bean állapot
nélküli volta lehetővé teszi az EJB
konténernek, hogy a bean objektumegyedet kedve szerint hozza
létre és pusztítsa el a kliensprogram
tudomása nélkül. Például
terhelésmegosztási mechanizmust használhat
és két hívás között úgy
dönthet, hogy a következő hívást a
szervercsoport másik gépe szolgálja ki. A kliens
következő hívását az első szerver EJB
konténere átirányítja a másik
szerver EJB konténeréhez, amely elővesz egy egyedet ebből
a típusú állapotnélküli kapcsolat
bean-ből és meghívja rajta a bean metódust. Ebben
az extrém példában a bean egyed még csak
nem is ugyanazon a számítógépen volt, ez is
mutatja, miért nem lehet az egyedváltozókat
állapotmegőrzésre használni.
Lássuk, hogy néz ki mindez a gyakorlatban! A kliens a bean-nel a JNDI katalóguson keresztül veszi fel a kapcsolatot. Minden EJB-nek két interfésze van, ezeket vezérlő (home) és távoli (remote) interfészeknek hívjuk. Valójában mindkét interfész elérhető távoli kliensekről. Az EJB specifikáció megköveteli, hogy a vezérlő és a távoli interfész mint különálló Jáva interfész is létezzen. A példánkban legyenek a következőek a nevek:
public void myMethod() throws RemoteException;
}
public MyEJB create()
throws javax.ejb.RemoteException, javax.ejb.CreateException;
}
Ha tehát meghívjuk a create metódust, kapunk egy referenciát egy MyEJB egyedre. A MyEJB egyeden tehát meghívhatjuk a myMethod metódust, ami a mi saját funkcionalitásunk. A kliens a MyEJBHome referenciát a JNDI-ből szerzi, ezen hívja a create-et majd az így kapott MyEJB referencián keresztül hívja a myMethod-ot. A pontos JNDI névről sajnos nem szól specifikáció, ezt alkalmazásszerver-specifikus módon kell megadni.
Context initial = new InitialContext();
Object objref = initial.lookup("java:myApp/MyEJBBean");
MyEJBHome home = (MyEJBHome)PortableRemoteObject.narrow(objref, MyEJBHome.class);
MyEJB remote = home.create();
remote.myMethod();
Mi van tehát a MyEJBBean-ben? A figyelmes olvasó mindjárt sejtheti, hogy a távoli és vezérlő interfész metódusai és az EJB által implementált metódusok között a kapcsolat bonyolultabb lehet. Közben van ugyanis az alkalmazásszerver és neki egy csomó dolga van a hívásunkkal. Minden alkalmazásszerver esetében a vezérlő és távoli interfészekre befutó hívások egy csonkegyedre (stub) kerülnek, melyet az alkalmazásszerver maga generál az EJB-hez tartozó adatokból, bean osztályokból és interfészekből. A csonk és az alkalmazásszerver együttműködése valósítja meg az alkalmazásszerver bonyolult funkcióit, pl. a Weblogic alkalmazásszervernél a csonk képes rájönni, ha az adott alkalmazásszervernél túlterhelés van és a szervercsoport másik gépére irányítani a hívást.
public class MyEJBBean implements SessionBean {
public void ejbCreate() {
...
}
public void ejbRemove() {
...
}
// ejbActivate és ejbPassivate nem hívódik meg állapotnélküli kapcsolat bean-nél, de a SessionBean interfész megköveteli
public void ejbActivate() {}
public void ejbPassivate() {}
public void setSessionContext( SessionContext sc ) {}
// Saját metódusunk
public void myMethod() {
...
}
}
Most nézzük meg, hogyan viszonyulnak egymáshoz a csonk és az EJB osztály metódusai.
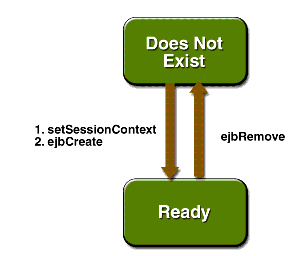
A kliens create() hívására a csonk meghívja a setSessionContext() majd az ejbCreate() MyEJBBean metódusokat. Ekkor a bean kész bármely MyEJBBean-t használó klienstől hívásokat fogadni. A konténer tetszése szerint pusztíthatja el a bean egyedet, ekkor ejbRemove() metódusát hívja meg.
Az állapot nélküli kapcsolat bean kezelése jelenti a legkisebb terhet az alkalmazásszerver számára, ezt az EJB típust ajánlott tehát a lehető leggyakrabban használni.
3.2. Állapottal rendelkező kapcsolat bean (stateful session
bean)
A kapcsolat bean-ek másik típusa az állapottal
rendelkező kapcsolat bean. A különbség az
állapot nélküli típushoz képest az,
hogy a bean megőrzi a klienshez rendeltségét és
egyedváltozóinak állapotát két
hívás között. Tehát ha van egy ilyen
programrészletünk:
remote.myMethod();
...
remote.myMethod();
az állapot nélküli bean-nél a két hívás két külön bean-hez futhat be, amelyeknek állapotai (egyedváltozói) különbözőek lehetnek. Ha véletlenül a két hívás ugyanahhoz a bean egyedhez futna be, akkor se garantálja semmi, hogy a két hívás között egy másik kliens nem használta a bean-t. Állapottal rendelkező bean esetén mindkét hívás azonos egyedváltozókat talál (vagy legalábbis konzisztens egyedváltozókat, hiszen a hívások meg is változtathatják azokat) és más kliens véletlenül nem használhatja ezt a bean egyedet, csak ha bean létrehozója átadta a bean referenciáját valaki másnak (bean referenciák átadásáról később). Természetesen a bean egyed nem feltétlenül ugyanaz, hiszen a bean-t esetleg át kellett mozgatni egy másik számítógépről vagy helyre kellett állítani tárolt formából. A SessionBean interfész végül is a Serializable leszármazottja, tehát a bean mozgatható az alkalmazásszerverek között vagy tárolóba menthető és onnan visszaállítható. Az állapot kezelése jelentős terhelést okoz az alkalmazásszervernek, így a bean életciklusa is jóval bonyolultabb.
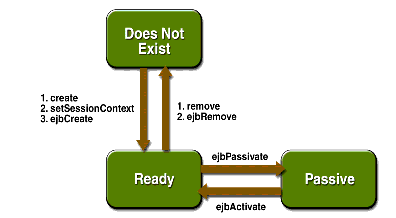
A kliens itt is create() hívással hozza létre a bean-t, amely végül most is a bean ejbCreate() metódusához fut be. Fontos itt kiemelni, hogy a create()-nek paraméteres változatai is lehetnek, ekkor az ejbCreate-ből is kell azonos paraméterszámú és paramétertípusú változat. Az állapottal rendelkező kapcsolat bean ejbCreate metódusa egyedváltozókba mentheti az ejbCreate paramétereit. Ekkor a bean készen áll az alkalmazáslogika metódusainak meghívására és mindaddig ebben az állapotban marad, amíg a kliens explicit vagy implicit módon el nem pusztítja. Explicit módon meghívhatja a remove() metódust a vezérlőinterfészen vagy egyszerűen eldobhatja a bean távoli interfészének a referenciáját. Mindkét esetben az alkalmazásszerver megszünteti a bean-t.
Minthogy a bean életciklusát a kliens vezérli, az alkalmazásszerver akkor sem pusztíthatja el a bean-t, ha erőforrásproblémái vannak. Ilyenkor a bean-t passziválják, vagyis az alkalmazásszerver elmenti az állapotát egy tárolóba és törli az egyedet. Ha a kliens újra meghív egy bean metódust, az alkalmazásszerver visszaállítja a bean állapotot, aktiválja a bean-t és csak utána kapja meg a bean a hívást. Passziválás előtt az ejbPassivate, aktiválás után (de még bármely egyéb metódus hívása előtt) az ejbActivate bean metódus hívódik meg.
3.3. Entitás
bean (entity bean)
A kapcsolat
bean-ek a klienssel való kapcsolattartásra valók,
az entitás bean ezzel szemben perzisztens adatokat
reprezentál. Egy entitás bean osztály kapcsolatban
van a perzisztens tároló (pl, adatbázisszerver)
bizonyos adatszerkezeteivel, alkalmazáslogika
metódusaiban ehhez az adatszerkezethez nyújt
hozzáférést. A leképezés az
entitás bean adatszerkezetei és a perzisztens
adatszerkezetek között lehet egyszerű vagy bonyolult, pl. egy
entitás bean jelképezhet egy táblának egy
sorát vagy akár több táblából
vett adatok kombinációját. Mindig igaz azonban,
hogy egy entitás bean osztály egyedei
megtalálhatók az elsődleges
kulcsuk (primary key) alapján. Az elsődleges kulcs maga
is lehet egy bonyolult adatszerkezet (pl. osztály sok
egyedváltozóval), de az EJB konténernek
képesnek kell lennie egyértelműen megtalálni a
bean egyedet az elsődleges kulcs ismeretében.
Az entitás bean életciklusa kissé bonyolultabb a két előző típusú bean-hez képest.
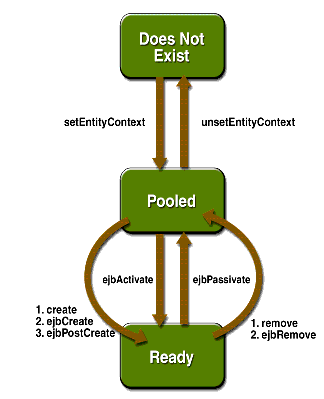
A findByPrimaryKey támogatása kötelező, ezen felül a bean további findByXXX kereső metódusokat támogathat. Minden, a vezérlő interfészen definiált findByXXX metódusnak kell legyen a bean osztályban egy ejbFindByXXX párja. A kereső metódusok Collection visszatérési értéket adnak vissza, amiben a keresési feltételnek megfelelő adatstruktúrák elsődleges kulcsai vannak. Ebből a findByPrimaryKey-jel lehetne bean egyedekhez jutni.
A bean egyedtároló és a passziválási/aktiválási mechanizmus azt eredményezi, hogy egy ideiglenes adattároló (cache) jön létre, amit az EJB alkalmazás okosan kihasználva jelentős sebességnövekedést érhet el. Tegyük fel, hogy a perzisztens tárolót csak az EJB alkalmazás éri el. Ekkor alkalmazható a Data Access Object (DAO) pattern, ami arról szól, hogy az adatbázist egy programozói interfész mögé rejtjük. Ez a programozói interfész az esetünkben az entitás bean, tehát az adatstruktúrát mindenki a bean egyedeken keresztül éri el. Ekkor olvasási műveletekre a bean egyedtároló cache-ként működik, amiből az olvasási műveleteket ki lehet elégíteni, hiszen az írási műveletek is a bean egyedeken keresztül haladnak. Ha pedig a szervercsoport más tagján van szükség a bean-re, az adatbázisból az aktuális állapot helyreállítható.
A bean egyed és a perzisztens tároló közötti szinkronizációra kétfajta megoldás létezik. Mostanáig a bean által vezérelt perzisztenciáról (BMP, bean managed persistence) beszéltünk. Ekkor a bean metódusai maguk felelősek a perzisztens tároló kezeléséért (pl. JDBC-t használhatnak az SQL adatbázis elérésére). Az EJB konténer támogatja a konténer által vezérelt perzisztenciát is (CMP, container-managed persistence). Ekkor a bean absztrakt getXXX, setXXX metódusokat tartalmaz, ezek mondják meg a konténernek a perzisztens mezőket. A kereső metódusok az SQL-hez hasonló EJB QL nyelven írják le a keresési feltételeket. A többi a konténer dolga, ezen információk alapján létrehozza a megfelelő (általa megfelelőnek talált) perzisztens adatszerkezeteket és az EJB QL kérdéseket a perzisztens tárolóhoz illeszkedő (pl. SQL) kifejezésekké fordítja. Ez nagyon szép, de a legtöbb konténernek konténer-specifikus adatokra is szüksége van, hogy a CMP-t megvalósíthassa és a konténer által generált adatszerkezetek gyakran nem olyan hatékonyak, mint a "kézzel" generáltak.
Az eseményvezérelt bean nagyon hasonlít az állapotnélküli kapcsolat bean-re. A bean-nek három metódust kell implementálnia: a már ismert ejbCreate() és ejbRemove() metódusokat és az onMessage() metódust, ami egy javax.jms.Message típusú paraméter kap. A JMS eseményeket Jáva alkalmazások generálhatják, így lehetőség van aszinkron események kezelésére is. EJB konténerek nem szabványos megoldásokkal rendelkeznek, ami különböző eseményekből (pl. hálózati események) eseményvezérelt bean-nel kezelhető JMS eseményeket gyártanak.
3.5. Bean-ek kommunikációja, lokális
interfészek
Ha a egy bean meg akar hívni egy másik bean-t,
ugyanúgy kell elérnie, mintha kliens lenne. Ki kell
vennie a vezérlő interfész címét a JNDI
katalógusból, létre kell hoznia vagy megkeresni a
bean-t és meg kell hívnia az alkalmazáslogika
metódust. A bean-hez tartozó telepítési
leíró (lásd később) megmondja, milyen
bean-eket hív ez a bean és a hivatkozott bean-eknek a
vezérlő interfészét beteszi a java:comp/env
kontextus alá. Minden bean különböző comp/env
kontextust lát, függően a telepítési
leíróban található adatoktól.
Ha egy bean saját magát oda akarja adni egy másik bean-nek, nem passzolhatja át a this referenciát, mert az esetleg a fogadó bean konténerében nem ismert (pl. a fogadó bean más gépen van). Egy csonk referenciáját adhatja oda, amit a kontextusából (SessionContext vagy EntityContext) szerezhet meg. Pl.:
public class WagonBean implements SessionBean {
SessionContext context;
...
public void setSessionContext(SessionContext sc) {
this.context = sc;
}
...
public void passItOn(Basket basket) {
...
basket.copyItems(context.getEJBObject());
}
Az EJB szépsége az, hogy az összes nyilvános bean interfészt (vezérlő vagy távoli) el lehet távolról érni, tehát nem szempont, hogy a bean éppen hol fut. Sajnos a távoli hívás idő- és erőforrásigényes, így igen lassúak lesznek az alkalmazások, még ha minden bean egy gépen van, akkor is. Felismervén ezt a problémát, bevezették a lokális interfészeket. A lokális interfészeket csak helyi hívásokkal lehet elérni. Ez azt jelenti, hogy a lokális interfészen át meghívott bean mindenképpen azon a gépen lesz, mint a hívó. Ez egyfelől gyors végrehajtást jelent, másfelől megölheti az alkalmazásszerver terheléskiegyensúlyozó logikáját, használata tehát csak kellő óvatossággal ajánlott. A lokális interfészek úgy néznek ki, mint a szokásos távoli vagy vezérlő interfészek, kivéve, hogy az EJBLocalObject és EJBLocalHome interfészeket bővítik és nem dobnak RemoteException-t.
Megjegyzendő, hogy az alkalmazás bean-ekre osztása nem azonos a szoftverprojekt során azonosított és implementálandó komponensekkel, több komponens kerülhet egy bean-be. Kisméretű bean-ek esetén sok időt tölt alkalmazásunk a konténer csonkjaiban, nagy bean-ek esetén rosszabb lesz a terheléskiegyensúlyozás. A bean modellt tehát nem szabad komponensmodellnek is tekinteni egyben, hanem inkább a terheléskiegyensúlyozási és hibatűrési funkcióira kell helyezni a hangsúlyt.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE ejb-jar PUBLIC '-//Sun Microsystems, Inc.//DTD Enterprise JavaBeans 2.0//EN' 'http://java.sun.com/dtd/ejb-jar_2_0.dtd'>
<ejb-jar>
<display-name>MyEJBBeans</display-name>
<enterprise-beans>
<session>
<display-name>MyStatelessSessionBean</display-name>
<ejb-name>SSBean</ejb-name>
<home>myproject.SSBHome</home>
<remote>myproject.SSB</remote>
<ejb-class>myproject.SSBBean</ejb-class>
<session-type>Stateless</session-type>
<env-entry>
<env-entry-name>someParms</env-entry-name>
<env-entry-type>java.lang.String</env-entry-type>
<env-entry-value>someParmValue</env-entry-value>
</env-entry>
<ejb-ref>
<ejb-ref-name>ejb/MyEntityBean</ejb-ref-name>
<ejb-ref-type>Entity</ejb-ref-type>
<home>myProject.EntHome</home>
<remote>myProject.Ent</remote>
<ejb-link>MyEntityBean</ejb-link>
</ejb-ref>
<session>
<entity>
<display-name>MyEntityBean</display-name>
<ejb-name>MyEntityBean</ejb-name>
<home>myProject.EntHome</home>
<remote>myProject.Ent</remote>
<ejb-class>myProject.EntBean</ejb-class>
<persistence-type>Bean</persistence-type>
<prim-key-class>java.lang.String</prim-key-class>
<reentrant>False</reentrant>
<resource-ref>
<description>Indexer DB</description>
<res-ref-name>jdbc/IndexDB</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
</entity>
</enterprise-beans>
</ejb-jar>
Ebben a példában két EJB-t deklaráltunk, a MyStatelessSessionBean és a MyEntityBean nevezetűt. Megfigyelhetjük, hogyan írjuk le a távoli és vezérlőinterfész, valamint az EJB osztály nevét. Figyeljük meg az env-entry elemet - az itt deklarált someParms string elem elérhető lesz a bean futása alatt, mint java:comp/env/someParms. Ugyancsak itt definiálhatjuk, milyen egyéb bean-eket akarunk elérni (ejb-ref). A példa szerinti ejb-ref elérhetővé teszi a MyStatelessSessionBean számára a MyEntityBean vezérlő interfészét a java:comp/env/ejb/MyEntityBean JNDI cím alatt.
Az EJB alkalmazásmodell lehetővé teszi EJB JAR-ok és WAR-ok összecomagolását alkalmazáscsomagokká. Egy ilyen csomag tartalmazza a webes interfészhez szükséges statikus adatokat és dinamikus tartalmat generáló kódot és az EJB-ket is. A WAR és EJB JAR fájlokat a JAR eszközzel össze kell csomagolni és alkalmazásleírót csatolni hozzá META-INF/application.xml néven. Íme egy példa:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE application PUBLIC '-//Sun Microsystems, Inc.//DTD J2EE Application 1.3//EN' 'http://java.sun.com/dtd/application_1_3.dtd'>
<application>
<display-name>App</display-name>
<description>My wonderful application</description>
<module>
<web>
<web-uri>myapp.war</web-uri>
<context-root>/jssearch</context-root>
</web>
</module>
<module>
<ejb>myapp-ejb.jar</ejb>
</module>
</application>
Az EJB-knek négy alaptípusa van:
- Állapot nélküli kapcsolat bean (stateless session bean)
- Állapottal rendelkező kapcsolat bean (stateful session bean)
- Entitás bean (entity bean)
- Üzenetvezérelt bean (message-driven bean)
3.1. Állapot nélküli kapcsolat bean (stateless
session bean)
Lássuk a legegyszerűbbet, az állapot nélküli
kapcsolat bean-t. Ez a bean lehetővé teszi metódusok
kontextus nélküli hívását,
tehát a metódushívások között a
konténer nem őriz állapotot, a kontextus csupán a
hívás során létezik. A kliensprogram a
bean-t a create() metódus meghívásával
létrehozza, majd az így kapott bean egyeden meghív
egy bean által implementált metódust. A
hívás során a bean egyedváltozói
megőrződnek, de egyáltalán nem garantált, hogy a
következő hívásnál ugyanazon a bean egyeden
hajtódik végre a hívás vagy hogy
közben a konténer nem adta-e oda a bean egyedet egy
másik kliensnek egy másik hívásra. A bean
egyedváltozói tehát nem használhatók
hívások közötti állapot
tárolására. A bean állapot
nélküli volta lehetővé teszi az EJB
konténernek, hogy a bean objektumegyedet kedve szerint hozza
létre és pusztítsa el a kliensprogram
tudomása nélkül. Például
terhelésmegosztási mechanizmust használhat
és két hívás között úgy
dönthet, hogy a következő hívást a
szervercsoport másik gépe szolgálja ki. A kliens
következő hívását az első szerver EJB
konténere átirányítja a másik
szerver EJB konténeréhez, amely elővesz egy egyedet ebből
a típusú állapotnélküli kapcsolat
bean-ből és meghívja rajta a bean metódust. Ebben
az extrém példában a bean egyed még csak
nem is ugyanazon a számítógépen volt, ez is
mutatja, miért nem lehet az egyedváltozókat
állapotmegőrzésre használni.Lássuk, hogy néz ki mindez a gyakorlatban! A kliens a bean-nel a JNDI katalóguson keresztül veszi fel a kapcsolatot. Minden EJB-nek két interfésze van, ezeket vezérlő (home) és távoli (remote) interfészeknek hívjuk. Valójában mindkét interfész elérhető távoli kliensekről. Az EJB specifikáció megköveteli, hogy a vezérlő és a távoli interfész mint különálló Jáva interfész is létezzen. A példánkban legyenek a következőek a nevek:
- MyEJBBean - Az EJB-t implementáló osztály. Állapotnélküli session bean esetén a MyEJBBean a SessionBean interfészt is implementálja.
- MyEJB - Az EJB távoli interfészét leíró Jáva interfész. A MyEJB bővíti a javax.ejb.EJBObject interfészt. A távoli interfész az alkalmazáslogika metódusait tartalmazza, ezek tehát a mi metódusaink. Minden metódusnak tudnia kell dobni java.rmi.RemoteException-t, hiszen a meghívás során távoli metódushívás történhet
public void myMethod() throws RemoteException;
}
- MyEJBHome - Az EJB vezérlő interfészét leíró Jáva interfész. A MyEJBHome így néz ki:
public MyEJB create()
throws javax.ejb.RemoteException, javax.ejb.CreateException;
}
Ha tehát meghívjuk a create metódust, kapunk egy referenciát egy MyEJB egyedre. A MyEJB egyeden tehát meghívhatjuk a myMethod metódust, ami a mi saját funkcionalitásunk. A kliens a MyEJBHome referenciát a JNDI-ből szerzi, ezen hívja a create-et majd az így kapott MyEJB referencián keresztül hívja a myMethod-ot. A pontos JNDI névről sajnos nem szól specifikáció, ezt alkalmazásszerver-specifikus módon kell megadni.
Context initial = new InitialContext();
Object objref = initial.lookup("java:myApp/MyEJBBean");
MyEJBHome home = (MyEJBHome)PortableRemoteObject.narrow(objref, MyEJBHome.class);
MyEJB remote = home.create();
remote.myMethod();
Mi van tehát a MyEJBBean-ben? A figyelmes olvasó mindjárt sejtheti, hogy a távoli és vezérlő interfész metódusai és az EJB által implementált metódusok között a kapcsolat bonyolultabb lehet. Közben van ugyanis az alkalmazásszerver és neki egy csomó dolga van a hívásunkkal. Minden alkalmazásszerver esetében a vezérlő és távoli interfészekre befutó hívások egy csonkegyedre (stub) kerülnek, melyet az alkalmazásszerver maga generál az EJB-hez tartozó adatokból, bean osztályokból és interfészekből. A csonk és az alkalmazásszerver együttműködése valósítja meg az alkalmazásszerver bonyolult funkcióit, pl. a Weblogic alkalmazásszervernél a csonk képes rájönni, ha az adott alkalmazásszervernél túlterhelés van és a szervercsoport másik gépére irányítani a hívást.
public class MyEJBBean implements SessionBean {
public void ejbCreate() {
...
}
public void ejbRemove() {
...
}
// ejbActivate és ejbPassivate nem hívódik meg állapotnélküli kapcsolat bean-nél, de a SessionBean interfész megköveteli
public void ejbActivate() {}
public void ejbPassivate() {}
public void setSessionContext( SessionContext sc ) {}
// Saját metódusunk
public void myMethod() {
...
}
}
Most nézzük meg, hogyan viszonyulnak egymáshoz a csonk és az EJB osztály metódusai.
A kliens create() hívására a csonk meghívja a setSessionContext() majd az ejbCreate() MyEJBBean metódusokat. Ekkor a bean kész bármely MyEJBBean-t használó klienstől hívásokat fogadni. A konténer tetszése szerint pusztíthatja el a bean egyedet, ekkor ejbRemove() metódusát hívja meg.
Az állapot nélküli kapcsolat bean kezelése jelenti a legkisebb terhet az alkalmazásszerver számára, ezt az EJB típust ajánlott tehát a lehető leggyakrabban használni.
3.2. Állapottal rendelkező kapcsolat bean (stateful session
bean)
A kapcsolat bean-ek másik típusa az állapottal
rendelkező kapcsolat bean. A különbség az
állapot nélküli típushoz képest az,
hogy a bean megőrzi a klienshez rendeltségét és
egyedváltozóinak állapotát két
hívás között. Tehát ha van egy ilyen
programrészletünk:remote.myMethod();
...
remote.myMethod();
az állapot nélküli bean-nél a két hívás két külön bean-hez futhat be, amelyeknek állapotai (egyedváltozói) különbözőek lehetnek. Ha véletlenül a két hívás ugyanahhoz a bean egyedhez futna be, akkor se garantálja semmi, hogy a két hívás között egy másik kliens nem használta a bean-t. Állapottal rendelkező bean esetén mindkét hívás azonos egyedváltozókat talál (vagy legalábbis konzisztens egyedváltozókat, hiszen a hívások meg is változtathatják azokat) és más kliens véletlenül nem használhatja ezt a bean egyedet, csak ha bean létrehozója átadta a bean referenciáját valaki másnak (bean referenciák átadásáról később). Természetesen a bean egyed nem feltétlenül ugyanaz, hiszen a bean-t esetleg át kellett mozgatni egy másik számítógépről vagy helyre kellett állítani tárolt formából. A SessionBean interfész végül is a Serializable leszármazottja, tehát a bean mozgatható az alkalmazásszerverek között vagy tárolóba menthető és onnan visszaállítható. Az állapot kezelése jelentős terhelést okoz az alkalmazásszervernek, így a bean életciklusa is jóval bonyolultabb.
A kliens itt is create() hívással hozza létre a bean-t, amely végül most is a bean ejbCreate() metódusához fut be. Fontos itt kiemelni, hogy a create()-nek paraméteres változatai is lehetnek, ekkor az ejbCreate-ből is kell azonos paraméterszámú és paramétertípusú változat. Az állapottal rendelkező kapcsolat bean ejbCreate metódusa egyedváltozókba mentheti az ejbCreate paramétereit. Ekkor a bean készen áll az alkalmazáslogika metódusainak meghívására és mindaddig ebben az állapotban marad, amíg a kliens explicit vagy implicit módon el nem pusztítja. Explicit módon meghívhatja a remove() metódust a vezérlőinterfészen vagy egyszerűen eldobhatja a bean távoli interfészének a referenciáját. Mindkét esetben az alkalmazásszerver megszünteti a bean-t.
Minthogy a bean életciklusát a kliens vezérli, az alkalmazásszerver akkor sem pusztíthatja el a bean-t, ha erőforrásproblémái vannak. Ilyenkor a bean-t passziválják, vagyis az alkalmazásszerver elmenti az állapotát egy tárolóba és törli az egyedet. Ha a kliens újra meghív egy bean metódust, az alkalmazásszerver visszaállítja a bean állapotot, aktiválja a bean-t és csak utána kapja meg a bean a hívást. Passziválás előtt az ejbPassivate, aktiválás után (de még bármely egyéb metódus hívása előtt) az ejbActivate bean metódus hívódik meg.
3.3. Entitás
bean (entity bean)
A kapcsolat
bean-ek a klienssel való kapcsolattartásra valók,
az entitás bean ezzel szemben perzisztens adatokat
reprezentál. Egy entitás bean osztály kapcsolatban
van a perzisztens tároló (pl, adatbázisszerver)
bizonyos adatszerkezeteivel, alkalmazáslogika
metódusaiban ehhez az adatszerkezethez nyújt
hozzáférést. A leképezés az
entitás bean adatszerkezetei és a perzisztens
adatszerkezetek között lehet egyszerű vagy bonyolult, pl. egy
entitás bean jelképezhet egy táblának egy
sorát vagy akár több táblából
vett adatok kombinációját. Mindig igaz azonban,
hogy egy entitás bean osztály egyedei
megtalálhatók az elsődleges
kulcsuk (primary key) alapján. Az elsődleges kulcs maga
is lehet egy bonyolult adatszerkezet (pl. osztály sok
egyedváltozóval), de az EJB konténernek
képesnek kell lennie egyértelműen megtalálni a
bean egyedet az elsődleges kulcs ismeretében.Az entitás bean életciklusa kissé bonyolultabb a két előző típusú bean-hez képest.
- Az entitás bean-t létrehozza az EJB konténer. Ezután meghívja a bean setEntityContext metódusát, amivel a bean megkapja az EntityContext egyedet, amin keresztül az EJB konténer kommunikálni fog vele. Ekkor a bean már használatra kész, de adathoz még nincs rendelve. A kész, de adathoz nem rendelt egyedek egy egyedtárolóban várakoznak sorukra.
- A kliens create() hívással entitás bean-t hoz létre. Ekkor az EJB konténer kiemel egy egyedet az egyedtárolóból és adathoz rendeli. Ehhez meghívja a bean ejbCreate metódusát, amely tipikusan kiszámítja az elsődleges kulcsot a hívási paraméterek alapján, inicializálja az egyedváltozókat és esetleg létrehozza az adatszerkezetet a perzisztens tárolóban. Az ejbCreate visszaadja a bean elsődleges kulcsát. Minden ejbCreate-hez kell tartozzon egy ejbPostCreate metódus is. Míg az ejbCreate futása alatt a bean még nincs adathoz rendelve, az ejbPostCreate során már igen, pl. le lehet kérdezni az elsődleges kulcsát.
- A bean egyed ekkor készen áll
alkalmazáslogika metódusok hívására.
Tipikusan egy alkalmazáslogika metódus manipulálja
a perzisztens tárolóban levő adatszerkezetet
felhasználva a bean egyedváltozóit, pl. elsődleges
kulcsát. Mielőtt alkalmazáslogika metódus
meghívódna, a konténet egy ejbLoad
hívással mindig szinkronizálja a bean
állapotát a perzisztens tárolóval, majd az
alkalmazáslogika metódus lefutása után az
ejbStore metódussal visszateszi az új állapotot az
adatbázisba. (megjegyzés: a valódi
működés ennél bonyolultabb. Az ejbLoad-ot a
tranzakció kezdetén hívják meg, az
ejbStore-t pedig a végén. Ezek absztrakt, EJB-szintű
tranzakciók. Az alkalmazáslogika metódusok
megmondhatják, hogy a hívásuk új
tranzakciós kontextust hoz-e létre vagy
felhasználja a meglevő kontextust). Ez szükséges,
minthogy az adatbázist közben mások is
módosíthatták a bean-től függetlenül,
azonban az állandó olvasás-írások
jelentős sebességcsökkenést okoznak.
Alkalmazásszerverek nem szabványos megoldásokat
kínálnak a problémára, a Weblogic
szervernél pl. megmondható, hogy ne töltse mindig
újra a bean állapotát.
- A bean-t passziválhatják. Ekkor a konténer meghívja az ejbStore, majd az ejbPassivate metódust és visszateszi a bean-t az egyedtárolóba. Ha passzivált bean-en próbálnak meghívni alkalmazáslogika metódust, a bean-t először aktiválják (ejbActivate) majd újratöltik az állapotát (ejbLoad).
- A kliens meghívhatja a remove() metódust a vezérlő interfészen. Ekkor a konténer meghívja az ejbRemove() metódust a bean-en, majd visszateszi a bean-t az egyedtárolóba. Az ejbRemove() implementációja általában törli az adatstruktúrákat a perzisztens tárolóból is.
A findByPrimaryKey támogatása kötelező, ezen felül a bean további findByXXX kereső metódusokat támogathat. Minden, a vezérlő interfészen definiált findByXXX metódusnak kell legyen a bean osztályban egy ejbFindByXXX párja. A kereső metódusok Collection visszatérési értéket adnak vissza, amiben a keresési feltételnek megfelelő adatstruktúrák elsődleges kulcsai vannak. Ebből a findByPrimaryKey-jel lehetne bean egyedekhez jutni.
A bean egyedtároló és a passziválási/aktiválási mechanizmus azt eredményezi, hogy egy ideiglenes adattároló (cache) jön létre, amit az EJB alkalmazás okosan kihasználva jelentős sebességnövekedést érhet el. Tegyük fel, hogy a perzisztens tárolót csak az EJB alkalmazás éri el. Ekkor alkalmazható a Data Access Object (DAO) pattern, ami arról szól, hogy az adatbázist egy programozói interfész mögé rejtjük. Ez a programozói interfész az esetünkben az entitás bean, tehát az adatstruktúrát mindenki a bean egyedeken keresztül éri el. Ekkor olvasási műveletekre a bean egyedtároló cache-ként működik, amiből az olvasási műveleteket ki lehet elégíteni, hiszen az írási műveletek is a bean egyedeken keresztül haladnak. Ha pedig a szervercsoport más tagján van szükség a bean-re, az adatbázisból az aktuális állapot helyreállítható.
A bean egyed és a perzisztens tároló közötti szinkronizációra kétfajta megoldás létezik. Mostanáig a bean által vezérelt perzisztenciáról (BMP, bean managed persistence) beszéltünk. Ekkor a bean metódusai maguk felelősek a perzisztens tároló kezeléséért (pl. JDBC-t használhatnak az SQL adatbázis elérésére). Az EJB konténer támogatja a konténer által vezérelt perzisztenciát is (CMP, container-managed persistence). Ekkor a bean absztrakt getXXX, setXXX metódusokat tartalmaz, ezek mondják meg a konténernek a perzisztens mezőket. A kereső metódusok az SQL-hez hasonló EJB QL nyelven írják le a keresési feltételeket. A többi a konténer dolga, ezen információk alapján létrehozza a megfelelő (általa megfelelőnek talált) perzisztens adatszerkezeteket és az EJB QL kérdéseket a perzisztens tárolóhoz illeszkedő (pl. SQL) kifejezésekké fordítja. Ez nagyon szép, de a legtöbb konténernek konténer-specifikus adatokra is szüksége van, hogy a CMP-t megvalósíthassa és a konténer által generált adatszerkezetek gyakran nem olyan hatékonyak, mint a "kézzel" generáltak.
3.4. Eseményvezérelt bean (message-driven bean)
Az EJB model legnagyobb problémája, hogy teljesen szinkron, a kliensek kérésekkel bombázzák a konténert, mire az válaszol. Aszinkron, a konténerből származó események kezelésére az eddigi EJB típusok nem alkalmasok. Az eseményvezérelt bean ezt a lyukat próbálja betömni. Ezt a bean típust elsősorban Java Messaging Service (JMS) üzenetek kezelésére tervezték. A JMS-ről most elég annyit tudnunk, hogy úgy működik, mint egy levelezőlista: a JMS-ben topic-nak hívott témákra akármilyen adatstruktúrát lehet küldeni, amelyek sorba állnak, majd a témára feliratkozott alkalmazások megkapják őket. Eseményvezérelt bean lehet feliratkozva egy témára, ekkor a JMS üzenetek hatására aktivizálódik. A bean életciklusát a konténer és a beérkező üzenetek vezérlik. Üzenet érkezésekor a konténer szerez egy szabad bean-t (gyárt egyet vagy elővesz egyet az egyedtárolóból) és odaadja az üzenetet. Minthogy a bean-t kliensek nem hívhatják meg, se vezérlő, se távoli interfésze nincsen, csak a bean osztály.Az eseményvezérelt bean nagyon hasonlít az állapotnélküli kapcsolat bean-re. A bean-nek három metódust kell implementálnia: a már ismert ejbCreate() és ejbRemove() metódusokat és az onMessage() metódust, ami egy javax.jms.Message típusú paraméter kap. A JMS eseményeket Jáva alkalmazások generálhatják, így lehetőség van aszinkron események kezelésére is. EJB konténerek nem szabványos megoldásokkal rendelkeznek, ami különböző eseményekből (pl. hálózati események) eseményvezérelt bean-nel kezelhető JMS eseményeket gyártanak.
3.5. Bean-ek kommunikációja, lokális
interfészek
Ha a egy bean meg akar hívni egy másik bean-t,
ugyanúgy kell elérnie, mintha kliens lenne. Ki kell
vennie a vezérlő interfész címét a JNDI
katalógusból, létre kell hoznia vagy megkeresni a
bean-t és meg kell hívnia az alkalmazáslogika
metódust. A bean-hez tartozó telepítési
leíró (lásd később) megmondja, milyen
bean-eket hív ez a bean és a hivatkozott bean-eknek a
vezérlő interfészét beteszi a java:comp/env
kontextus alá. Minden bean különböző comp/env
kontextust lát, függően a telepítési
leíróban található adatoktól.Ha egy bean saját magát oda akarja adni egy másik bean-nek, nem passzolhatja át a this referenciát, mert az esetleg a fogadó bean konténerében nem ismert (pl. a fogadó bean más gépen van). Egy csonk referenciáját adhatja oda, amit a kontextusából (SessionContext vagy EntityContext) szerezhet meg. Pl.:
public class WagonBean implements SessionBean {
SessionContext context;
...
public void setSessionContext(SessionContext sc) {
this.context = sc;
}
...
public void passItOn(Basket basket) {
...
basket.copyItems(context.getEJBObject());
}
Az EJB szépsége az, hogy az összes nyilvános bean interfészt (vezérlő vagy távoli) el lehet távolról érni, tehát nem szempont, hogy a bean éppen hol fut. Sajnos a távoli hívás idő- és erőforrásigényes, így igen lassúak lesznek az alkalmazások, még ha minden bean egy gépen van, akkor is. Felismervén ezt a problémát, bevezették a lokális interfészeket. A lokális interfészeket csak helyi hívásokkal lehet elérni. Ez azt jelenti, hogy a lokális interfészen át meghívott bean mindenképpen azon a gépen lesz, mint a hívó. Ez egyfelől gyors végrehajtást jelent, másfelől megölheti az alkalmazásszerver terheléskiegyensúlyozó logikáját, használata tehát csak kellő óvatossággal ajánlott. A lokális interfészek úgy néznek ki, mint a szokásos távoli vagy vezérlő interfészek, kivéve, hogy az EJBLocalObject és EJBLocalHome interfészeket bővítik és nem dobnak RemoteException-t.
Megjegyzendő, hogy az alkalmazás bean-ekre osztása nem azonos a szoftverprojekt során azonosított és implementálandó komponensekkel, több komponens kerülhet egy bean-be. Kisméretű bean-ek esetén sok időt tölt alkalmazásunk a konténer csonkjaiban, nagy bean-ek esetén rosszabb lesz a terheléskiegyensúlyozás. A bean modellt tehát nem szabad komponensmodellnek is tekinteni egyben, hanem inkább a terheléskiegyensúlyozási és hibatűrési funkcióira kell helyezni a hangsúlyt.
4. EJB-k csomagolása
Mint láthattuk, az EJB-k csupán programdarabkák, amelyeket az EJB konténer kapcsol össze. Hogy ezt megtehesse, a konténernek elég sok mindent tudnia kell a bean-ekről. Az EJB azt a megoldást választotta, hogy a lefordított EJB-k mellé telepítésleírót tesz. A telepítésleíró egy XML fájl, ami minden információt tárol a bean-ekről, amit a konténernek tudnia kell és nem szedhető ki a bean class fájlból magából. A telepítésleíró valamint a bean class fájlok egy JAR-ba vannak csomagolva, a telepítésleíró helye fix: META-INF/ejb-jar.xml. Nézzünk meg egy egyszerű példát ejb-jar.xml-re!<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE ejb-jar PUBLIC '-//Sun Microsystems, Inc.//DTD Enterprise JavaBeans 2.0//EN' 'http://java.sun.com/dtd/ejb-jar_2_0.dtd'>
<ejb-jar>
<display-name>MyEJBBeans</display-name>
<enterprise-beans>
<session>
<display-name>MyStatelessSessionBean</display-name>
<ejb-name>SSBean</ejb-name>
<home>myproject.SSBHome</home>
<remote>myproject.SSB</remote>
<ejb-class>myproject.SSBBean</ejb-class>
<session-type>Stateless</session-type>
<env-entry>
<env-entry-name>someParms</env-entry-name>
<env-entry-type>java.lang.String</env-entry-type>
<env-entry-value>someParmValue</env-entry-value>
</env-entry>
<ejb-ref>
<ejb-ref-name>ejb/MyEntityBean</ejb-ref-name>
<ejb-ref-type>Entity</ejb-ref-type>
<home>myProject.EntHome</home>
<remote>myProject.Ent</remote>
<ejb-link>MyEntityBean</ejb-link>
</ejb-ref>
<session>
<entity>
<display-name>MyEntityBean</display-name>
<ejb-name>MyEntityBean</ejb-name>
<home>myProject.EntHome</home>
<remote>myProject.Ent</remote>
<ejb-class>myProject.EntBean</ejb-class>
<persistence-type>Bean</persistence-type>
<prim-key-class>java.lang.String</prim-key-class>
<reentrant>False</reentrant>
<resource-ref>
<description>Indexer DB</description>
<res-ref-name>jdbc/IndexDB</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
</entity>
</enterprise-beans>
</ejb-jar>
Ebben a példában két EJB-t deklaráltunk, a MyStatelessSessionBean és a MyEntityBean nevezetűt. Megfigyelhetjük, hogyan írjuk le a távoli és vezérlőinterfész, valamint az EJB osztály nevét. Figyeljük meg az env-entry elemet - az itt deklarált someParms string elem elérhető lesz a bean futása alatt, mint java:comp/env/someParms. Ugyancsak itt definiálhatjuk, milyen egyéb bean-eket akarunk elérni (ejb-ref). A példa szerinti ejb-ref elérhetővé teszi a MyStatelessSessionBean számára a MyEntityBean vezérlő interfészét a java:comp/env/ejb/MyEntityBean JNDI cím alatt.
Az EJB alkalmazásmodell lehetővé teszi EJB JAR-ok és WAR-ok összecomagolását alkalmazáscsomagokká. Egy ilyen csomag tartalmazza a webes interfészhez szükséges statikus adatokat és dinamikus tartalmat generáló kódot és az EJB-ket is. A WAR és EJB JAR fájlokat a JAR eszközzel össze kell csomagolni és alkalmazásleírót csatolni hozzá META-INF/application.xml néven. Íme egy példa:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE application PUBLIC '-//Sun Microsystems, Inc.//DTD J2EE Application 1.3//EN' 'http://java.sun.com/dtd/application_1_3.dtd'>
<application>
<display-name>App</display-name>
<description>My wonderful application</description>
<module>
<web>
<web-uri>myapp.war</web-uri>
<context-root>/jssearch</context-root>
</web>
</module>
<module>
<ejb>myapp-ejb.jar</ejb>
</module>
</application>